

Merging PDF files is a task that can save you time and keep your documents well-organized.
In this tutorial, I’ll walk you through how to set up Python on your computer and use a script to merge two or more PDF files into one.
So We’ll be using the PyPDF2 library, and by the end, you’ll have a clear understanding of how to run the code on your terminal.
Setting Up Python on Your Computer
If you don’t have Python installed yet, follow these steps:
- Download the latest version of Python from the official Python website.
- Then Install it by following the instructions for your operating system (Windows, macOS, or Linux).
- And Also Make sure to check the option that says “Add Python to PATH” during installation.
- Then To verify if Python is installed correctly, open your terminal (or command prompt) and type:bashCopy code
python --versionThis should display the installed version of Python.
Installing PyPDF2
Once Python is installed, you can verify the installation by opening your terminal (or command prompt) and typing:
python --version
This will display the installed version of Python.
Installing PyPDF2
Now that Python is set up, the next step is to install the PyPDF2 library, which will allow us to manipulate PDF files. To install it, open your terminal (or command prompt) and run the following command:
pip install PyPDF2
This installs PyPDF2 on your system, which is crucial for merging PDFs. You can find more information on this library in the official PyPDF2 documentation.
Breaking Down the Code
Now, let’s break down the code that will help you merge your PDF files. Here’s how it works, step by step:
import PyPDF2
import os
import PyPDF2: This imports the PyPDF2 library, providing the tools needed to manipulate PDF files.import os: This imports theosmodule, which allows your script to interact with the file system, helping you access the PDF files in the specified folder.
Next, we define a function that merges the PDFs:
def merge_pdfs_in_folder(folder_path, output_filename):
merger = PyPDF2.PdfMerger()
def merge_pdfs_in_folder(folder_path, output_filename):: This function merges all the PDF files in the folder specified byfolder_path, saving the result asoutput_filename.merger = PyPDF2.PdfMerger():: This creates an instance of thePdfMergerobject, which is responsible for combining the PDF files.
Now, we loop through each file in the folder to add all the PDFs to the merger:
for file in os.listdir(folder_path):
if file.endswith('.pdf'):
file_path = os.path.join(folder_path, file)
merger.append(file_path)
print(f"Adding: {file}")
for file in os.listdir(folder_path):: This loop iterates through every file in the folder specified byfolder_path.if file.endswith('.pdf'):: This checks if the current file is a PDF by looking at the file extension.file_path = os.path.join(folder_path, file):: This constructs the full path to each PDF file.merger.append(file_path):: This adds the PDF to the merger.print(f"Adding: {file}"): A message is printed for each file, showing that it’s being added to the merge process.
Finally, we save the merged PDF:
merger.write(output_filename)
print(f"Merged PDF saved as: {output_filename}")
merger.write(output_filename):: This command writes the merged PDF to the output file.print(f"Merged PDF saved as: {output_filename}"): Once the file is saved, this message confirms that the process is complete.
Full Code Example
Here’s the complete code that you can copy and run:
import PyPDF2
import os
def merge_pdfs_in_folder(folder_path, output_filename):
merger = PyPDF2.PdfMerger()
for file in os.listdir(folder_path):
if file.endswith('.pdf'):
file_path = os.path.join(folder_path, file)
merger.append(file_path)
print(f"Adding: {file}")
merger.write(output_filename)
print(f"Merged PDF saved as: {output_filename}")
# Specify the folder path containing PDFs
folder_path = r'C:\Users\Micheal\Desktop\testpdf'
merge_pdfs_in_folder(folder_path, 'merged_output.pdf')
Running the Code
To run the code, follow these steps:
- Save the code in a file with the
.pyextension, for example,merge_pdfs.py. - Open your terminal (or command prompt) and navigate to the folder where the script is saved.
- Run the script by typing:bashCopy code
python merge_pdfs.py
Make sure to adjust the folder path in the script (folder_path) to point to the folder where your PDFs are located. After running the script, you should see the merged PDF in the same folder with the name merged_output.pdf.
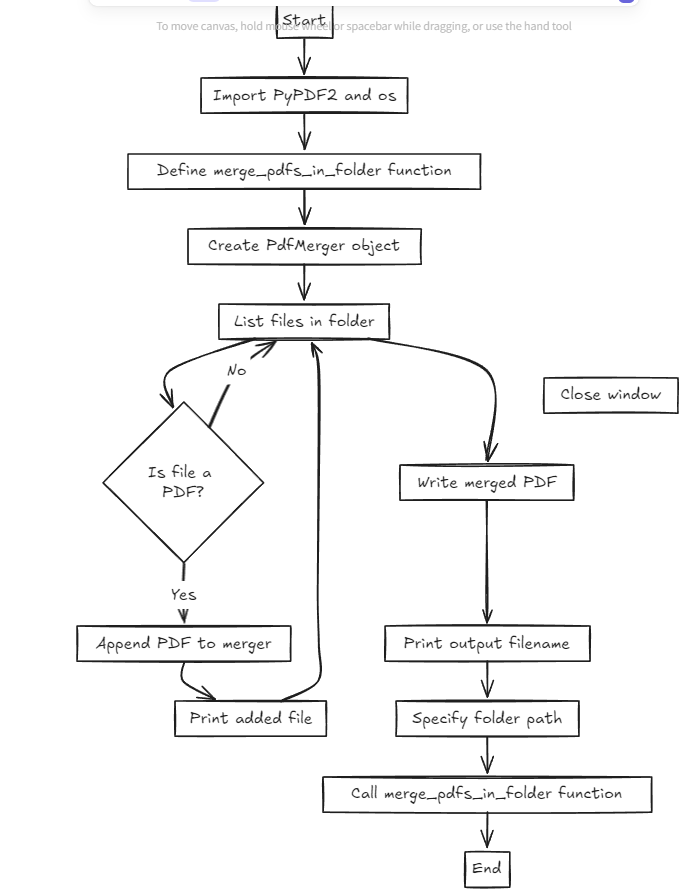
And here is the flow chart of the code
Get access to the script
To make it even easier for you to get started, we’ve uploaded the Excel Data Cleaner and Copier script to our GitHub account. Here’s how you can find and use it:
Visit Our GitHub Repository
- Go to GitHub: Open your web browser and visit our GitHub repository at https://github.com/michealtal/Pdf_Merger.git
- Explore the Repository: You’ll see a list of files and folders in the repository. Look for the file named Index.py
Result
Image of Pdf Before Combining

this is the second single pdf before combining

After Running the script
Once the script finishes running, you’ll find the merged PDF file in the location you specified. If you had multiple PDF files in the folder, they should now be combined into one single document.

Conclusion
Merging PDFs using Python is a quick and efficient way to handle multiple documents at once. With just a few lines of code, you can merge any number of PDF files into one, making your life a bit easier. Be sure to check out the official documentation for Python and PyPDF2 for more advanced options and features.
If you like blog post like this then you would love our other blog post like How to Automate Image Editing in Python: A Beginner’s Guide